
Speex is a free audio codec which provides high level of compression with
good sound quality for speech encoding and decoding.
Concepts
Before introducing all the Speex features, here are some con cepts in speech coding that help better understand the rest of the manual.
Although some are general concepts in speech/audio processing, others are specific to Speex.
Sampling rate
The sampling rate expressed in Hertz (Hz) is the number of samples taken from a signal per second.
For a sampling rate of Fs kHz, the highest frequency that can be represented is equal to Fs/2 kHz (Fs/2 is known as the Nyquist frequency).
This is a fundamental property in signal processing and is described by the sampling theorem.
Speex is mainly designed for three different sampling rates: 8 kHz, 16 kHz, and 32 kHz.
The se are respectively refered to as narrowband, wideband and ultra-wideband.
Bit-rate
When encoding a speech signal, the bit-rate is defined as the number of bits per unit of time required to encode the speech.
It is measured in bits per second (bps), or generally kilobits per second.
It is important to make the distinction between kilobits per second (kbps) and kilobytes per second (kBps).
Quality (variable)
Speex is a lossy codec, which means that it achives compression at the expense of fidelity of the input speech signal.
Unlike some other speech codecs, it is possible to control the trade off made between quality and bit-rate.
The Speex encoding process is controlled most of the time by a quality parameter that ranges from 0 to 10.
In constant bit-rate (CBR) operation, the quality parameter is an integer, while for variable bit-rate (VBR), the parameter is a float.
Complexity (variable)
With Speex, it is possible to vary the complexity allowed for the encoder.
This is done by controlling how the search is performed with an integer ranging from 1 to 10 in a way that’s similar to the -1 to -9 options to gzip and bzip2 compression utilities. For normal use, the noise level at complexity 1 is between 1 and 2 dB higher than at complexity 10, but the CPU requirements for complexity 10 is about 5 times higher than for complexity 1.
In practice, the best trade-off is between complexity 2 and 4, though higher settings are often useful when encoding non-speech sounds like DTMF tones.
Variable Bit-Rate (VBR)
Variable bit-rate (VBR) allows a codec to change its bit-rate dynamically to adapt to the “difficulty” of the audio being encoded.
In the example of Speex, sounds like vowels and high-energy transients require a higher bit-rate to achieve good quality, while fricatives (e.g. s,f sounds) can be coded adequately with less bits. For this reason, VBR can achive lower bit-rate for the same quality, or a better quality for a certain bit-rate.
Despite its advantages, VBR has two main drawbacks: first, by only specifying quality, there’s no guaranty about the final average bit-rate. Second, for some real-time applications like voice over IP (VoIP), what counts is the maximum bit-rate, which must be low enough for the communication channel.
Average Bit-Rate (ABR)
Average bit-rate solves one of the problems of VBR, as it dynamically adjusts VBR quality in order to meet a specific target bit-rate.
Because the quality/bit-rate is adjusted in real-time (open-loop), the global quality will be slightly lower than that obtained by encoding in VBR with exactly the right quality setting to meet the target average bit-rate.
Voice Activity Detection (VAD)
When enabled, voice activity detection detects whether the audio being encoded is speech or silence/background noise.
VAD is always implicitly activated when encoding in VBR, so the option is only useful in non-VBR operation.
In this case, Speex detects non-speech periods and encode
them with just enough bits to reproduce the background noise. This is called “comfort noise generation” (CNG).
Discontinuous Transmission (DTX)
Discontinuous transmission is an addition to VAD/VBR operation, that allows to stop transmitting completely when the background noise is stationary. In file-based operation, since we cannot just stop writing to the file, only 5 bits are used for such frames (corresponding to 250 bps).
Perceptual enhancement
Perceptual enhancement is a part of the decoder which, when turned on, attempts to reduce the perception of the noise/distortion produced by the encoding/decoding process.
In most cases, perceptual enhancement brings the sound further from the original objectively (e.g. considering only SNR), but in the end it still sounds better (subjective improvement).
Latency and algorithmic delay
Every speech codec introduces a delay in the transmission.
For Speex, this delay is equal to the frame size, plus some amount of “look-ahead” required to process each frame.
In narrowband operation (8 kHz), the delay is 30 ms, while for wideband (16 kHz), the delay is 34 ms. These values don’t account for the CPU time it takes to encode or decode the frames.
Codec
The main characteristics of Speex can be summarized as follows:
• Free software/open-source, patent and royalty-free
• Integration of narrowband and wideband using an embedded bit-stream
• Wide range of bit-rates available (from 2.15 kbps to 44 kbps)
• Dynamic bit-rate switching (AMR) and Variable Bit-Rate (VBR) operation
• Voice Activity Detection (VAD, integrated with VBR) and discontinuous transmission (DTX)
• Variable complexity
• Embedded wideband structure (scalable sampling rate)
• Ultra-wideband sampling rate at 32 kHz
• Intensity stereo encoding option
• Fixed-point implementation
Platforms
Speex is known to compile and work on a large number of architectures, both floating-point and fixed-point.
In general, any architecture that can natively compute the multiplication of two signed 16-bit numbers (32-bit result) and runs at a sufficient clock rate (architecture-dependent) is capable of running Speex.
Architectures on which Speex is known to work (it probably works on many others) are:
• x86 & x86-64
• Power
• SPARC
• ARM
• Blackfin
• Coldfire (68k family)
• TI C54xx & C55xx
• TI C6xxx
• TriMedia (experimental)
Operating systems on top of which Speex is known to work include (it probably works on many others):
• Linux
• μClinux
• MacOS X
• BSD
• Other UNIX/POSIX variants
• Symbian
The reference manual of SPEEX is here.
(From: SPEEX.ORG)
–
Speex Encoder
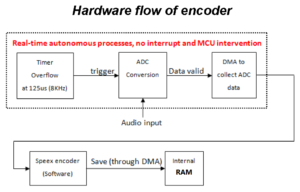
Speed vs. Memory Size
The memory size of a voice recording can be calculated as shown below:
Time interval between samples (8 kbps) = 1s/8000 = 125μs (16 bits per sample)
Frame length = 160 samples (16 bit) x 125μs = 20 ms
One frame will compress to 20 bytes (8 kbps).
Time per byte = 20 ms / 20 bytes = 1 ms / byte
Example:
60 seconds 8 kbps Speex encoded voice data requires 60 / 1ms = 60000 bytes (58.6 KB)
Number of frames = 60s / 20ms = 3000 frames
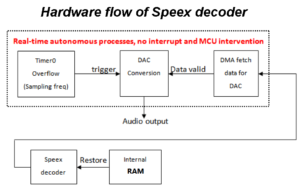
Speex Decoder
The Speex decoder consists of an audio output interface and speech decoding module.
In this application the embedded 12 bit DAC is use for audio output interface whereas the Speex decoder software uses for speech decoding module.
–
SPEEX on STM32
STM released the SPEEX library but is necessary request it directly to STM.
Below there are some references regarding STM32 Speex library.


NOTE
- FP-AUD-SMARTMIC1 – This software package implements a complete application targeting advanced processing for MEMS microphone arrays, including digital MEMS microphone acquisition (Speex), beamforming, source localization and acoustic echo cancellation.
– - Here there is a speex codec for stm32f4.
I don’t know who released it and I don’t know if they works.